The term machine learning – often abbreviated as ML – is among IoT, AI and others in its ubiquity and, equally, its ambiguity. The term is frequently marketed, and yet frequently glossed over. So let’s start from a baseline: machine learning describes software algorithms capable of detecting and analysing patterns from data. Through this information, predictive behaviour is developed. Every connection, interaction and incident prepare the algorithm for the future: machine learning, in a literal sense, enables computers, systems and networks to learn from experience.
Scrutinizer by Plixer’s new modules introduce new ML capabilities and, with them, significant implications for network security and optimisation as a whole. In this piece, we’ll be looking at the new machine learning capabilities of Scrutinizer, how it can be used to derive further insights from NetFlox, IPFIX and packet data, and how these insights can lead to network and security optimisations.
New intelligence modules
We recently wrote about Scrutinizer’s new network intelligence and security intelligence modules. They work by collecting flow or metadata collected by Scrutinizer, which is then streamed to a separate ML engine (which is also able to accept data streams from third parties to maximise learning). This data is then used by network and security teams to gain a real-time understanding of network traffic and incidents, as well as profiling traffic patterns, automating ticket creation and addressing network saturation.
But any diligent network manager may be left wondering: how? How does Scrutinizer take large quantities of data and turn it into a self-regulating (for the most part) system of alerts? Human input is an increasingly scarce resource. The more automation built into a network security and analysis solution, the better optimised a network – as well as the organisation’s bottom line – becomes.
How are large data sets handled?
The answer is K-means clustering: an unsupervised machine learning algorithm able to process large datasets like NetFlow through the use of data clusters. A cluster is a group of data points with the shortest possible distance to a fixed point – the centroid – with the cluster’s strength based on the distance and overlap compared to other clusters. This data is assessed by the algorithm, which assesses and assigns each data point to a cluster. The clusters are then used to assess the distance from the nearest centroid (or, more simply, the mean).
Through clusters, models are created that determine the optimal relationship between points of data, and combine them accordingly. To determine the significance of both normal and abnormal traffic in these models, meanwhile, a theorem called Chebyshev’s Inequality is used to establish thresholds. This allows alarms to be set and tuned, sensitive to standard deviations from the model and, ultimately, significantly reducing the number of false positives. You can read more about Chebyshev’s Inequality theorem here.
Forecasting
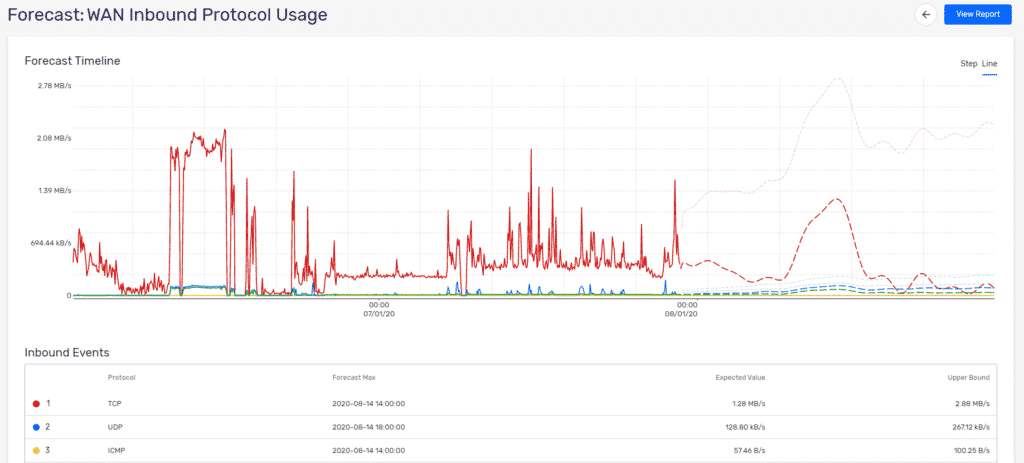
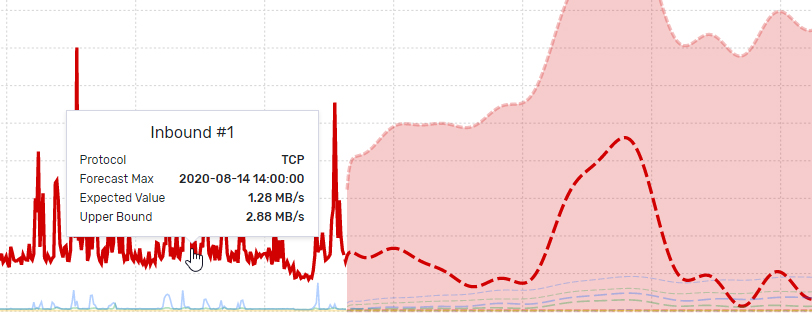
In the end, what these data set models make possible is forecasting. Increasingly, forecasting – as a pre-emptive, proactive approach to network management – is essential in network performance and security optimisation. Scrutinizer’s new ML feature set considers long-term traffic patterns to identify resource utilisation changes in advance, and issue alerts accordingly. This is one step forward in enabling network managers to automate – and, thereby, future proof – their network, reducing the human resource of management whilst maximising the performance and security of global networks.
To learn more about Scrutinizer by Plixer, its features – both old and new – and how to incorporate it into your network for maximum results, contact us today.
